SpaCy¶
SpaCy is an industrial friendly open source framework for doing NLP, and you can read more about it on their homesite or gitHub.
This project supports a Danish spaCy model that can easily be loaded with the DaNLP package.
Support for Danish directly in the spaCy framework is realeased under spacy 2.3
Note that the two models are not the same, e.g. the spaCy model in DaNLP performs better on Named Entity Recognition due to more training data. However the extra training data is not open source and can therefore not be included in the spaCy framework itself, as it contravenes the guidelines.
The spaCy model comes with tokenization, dependency parsing, part of speech tagging , word vectors and name entity recognition.
The model is trained on the Danish Dependency Treebank (DaNe), and with additional data for NER which originates from news articles form a collaboration with InfoMedia.
For comparison to other models and additional information of the tasks, check out the task individual pages for word embeddings, named entity recognition, part of speech tagging and dependency parsing.
The DaNLP github also provides a version of the spaCy model which contains a sentiment classifier, read more about it in the sentiment analysis docs.
Performance of the spaCy model¶
The following lists the performance scores of the spaCy model provided in DaNLP pakage on the Danish Dependency Treebank (DaNe) test set. The scores and elaborating scores can be found in the file meta.json that is shipped with the model when it is downloaded.
| Task | Measures | Scores |
|---|---|---|
| Dependency parsing | UAS | 81.63 |
| Dependency parsing | LAS | 77.22 |
| Part of speech tags | accuracy | 96.40 |
| Named entity recognition | F1 | 80.50 |
🐣 Getting started with the spaCy model¶
Below is some small snippets to get started using the spaCy model within the DaNLP package. More information about using spaCy can be found on spaCy’s own page.
First load the libraries and the model
# Import libaries
from danlp.models import load_spacy_model
from spacy.gold import docs_to_json
from spacy import displacy
#Download and load the spaCy model using the DaNLP wrapper fuction
nlp = load_spacy_model()
Use the model to determined linguistic features
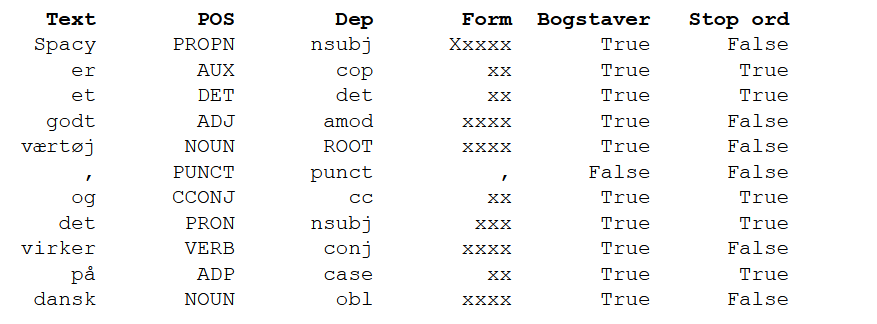
# Construct the text to a container "Doc" object
doc = nlp("Spacy er et godt værtøj,og det virker på dansk")
# prepare some pretty printing
features=['Text','POS', 'Dep', 'Form', 'Bogstaver', 'Stop ord']
head_format ="\033[1m{!s:>11}\033[0m" * (len(features) )
row_format ="{!s:>11}" * (len(features) )
print(head_format.format(*features))
# printing for each token in det docs the coresponding linguistic features
for token in doc:
print(row_format.format(token.text, token.pos_, token.dep_,
token.shape_, token.is_alpha, token.is_stop,))
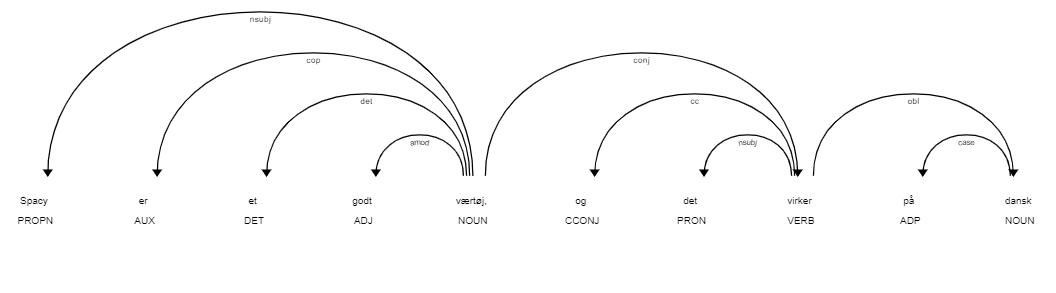
Visualizing the dependency tree
# the spaCy framework provides a nice visualization tool!
# This is run in a terminal, but if run in jupyter use instead display.render
displacy.serve(doc, style='dep')
Here is an example of using Named entity recognitions . You can read more about NER in the specific doc.
doc = nlp('Jens Peter Hansen kommer fra Danmark og arbejder hos Alexandra Instituttet')
for tok in doc:
print("{} {}".format(tok,tok.ent_type_))
# output
Jens PER
Peter PER
Hansen PER
kommer
fra
Danmark LOC
og
arbejder
hos
Alexandra ORG
Instituttet ORG
🐣 Start training your own text classification model¶
The spaCy framework provides an easy command line tool for training an existing model, for example by adding a text classifier. This short example shows how to do so using your own annotated data. It is also possible to use any static embedding provided in the DaNLP wrapper.
As an example we will use a small dataset for sentiment classification on twitter. The dataset is under development and will be added in the DaNLP package when ready, and the spacy model will be updated with the classification model as well. A first verison of a spacy model with a sentiment classifier can be load with the danlp wrapper, read more about it in the sentiment analysis docs.
The first thing is to convert the annotated data into a data format readable by spaCy
Imagine you have the data in an e.g csv format and have it split in development and training part. Our twitter data has (in time of creating this snippet) 973 training examples and 400 evaluation examples, with the following labels : ‘positive’ marked by 0, ‘neutral’ marked by 1, and ‘negative’ marked by 2. Loaded with pandas dataFrame it looks like this:

It needs to be converted into the format expected by spaCy for training the model, which can be done as follows:
#import libaries
import srsly
import pandas as pd
from danlp.models import load_spacy_model
from spacy.gold import docs_to_json
# load the spaCy model
nlp = load_spacy_model()
nlp.disable_pipes(*nlp.pipe_names)
sentencizer = nlp.create_pipe("sentencizer")
nlp.add_pipe(sentencizer, first=True)
# function to read pandas dataFrame and save as json format expected by spaCy
def prepare_data(df, outputfile):
# choose the name of the columns containg the text and labels
label='polarity'
text = 'text'
def put_cat(x):
# adapt the name and amount of labels
return {'positiv': bool(x==0), 'neutral': bool(x==1), 'negativ': bool(x==2)}
cat = list(df[label].map(put_cat))
texts, cats= (list(df[text]), cat)
#Create the container doc object
docs = []
for i, doc in enumerate(nlp.pipe(texts)):
doc.cats = cats[i]
docs.append(doc)
# write the data to json file
srsly.write_json(outputfile,[docs_to_json(docs)])
# prepare both the training data and the evaluation data from pandas dataframe (df_train and df_dev) and choose the name of outputfile
prepare_data(df_train, 'train_sent.json')
prepare_data(df_dev, 'eval_dev.json')
The data now looks like this cutted snippet:

Ensure you have the models and embeddings downloaded
The spaCy model and the embeddings must be downloaded. If you have done so it can be done by running the following commands. It will by default be placed in the cache directory of DaNLP, eg. “/home/USERNAME/.danlp/”.
from danlp.models import load_spacy_model
from danlp.models.embeddings import load_wv_with_spacy
#download the sapcy model
nlp = load_spacy_model()
# download the static (non subword) embedding of your choice
word_embeddings = load_wv_with_spacy('cc.da.wv')
Now train the model through the terminal
Now train the model throught the terminal by pointing to the path of the desired output directory, the converted training data, the converted development data, the base model and the embedding. The specify that the trainings pipe. See more parameter setting here .
python -m spacy train da spacy_sent train.json test.json -b '/home/USERNAME/.danlp/spacy' -v '/home/USERNAME/.danlp/cc.da.wv.spacy' --pipeline textcat
Using the trained model
Load the model from the specified output directory.
import spacy
#load the trained model
output_dir ='spacy_sent/model-best'
nlp2 = spacy.load(output_dir)
#use the model for prediction
def predict(x):
doc = nlp2(x)
return max(doc.cats.items(), key=operator.itemgetter(1))[0]
predict('Vi er glade for spacy!')
#'positiv'