Dependency Parsing & Noun Phrase Chunking¶
Dependency Parsing¶
Dependency parsing is the task of extracting a dependency parse of a sentence. It is typically represented by a directed graph that depicts the grammatical structure of the sentence; where nodes are words and edges define syntactic relations between those words. A dependency relation is a triplet consisting of: a head (word), a dependent (another word) and a dependency label (describing the type of the relation).
| Model | Train Data | License | Trained by | Tags | DaNLP |
|---|---|---|---|---|---|
| SpaCy | Danish Dependency Treebank | MIT | Alexandra Institute | 39 Universal dependencies | ✔️ |
| DaCy | Danish Dependency Treebank | Apache v2 | Center for Humanities Computing Aarhus, K. Enevoldsen | 39 Universal dependencies | ❌ |
| Stanza | Danish Dependency Treebank | Apache v2 | Stanford NLP Group | 39 Universal dependencies | ❌ |
The model has been trained on the Danish UD treebank which have been annotated with dependencies following the Universal Dependency scheme. It uses 39 dependency relations.
Noun Phrase Chunking¶
Chunking is the task of grouping words of a sentence into syntactic phrases (e.g. noun-phrase, verb phrase).
Here, we focus on the prediction of noun-phrases (NP). Noun phrases can be pronouns (PRON), proper nouns (PROPN) or nouns (NOUN) – potentially bound with other tokens that act as modifiers, e.g., adjectives (ADJ) or other nouns.
In sentences, noun phrases are generally used as subjects (nsubj) or objects (obj) (or complements of prepositions).
Examples of noun-phrases :
en
bog(NOUN)en
god bog(ADJ+NOUN)Lines bog(PROPN+NOUN)
NP-chunks can be deduced from dependencies. We provide a convertion function – from dependencies to NP-chunks – thus depending on a dependency model.
Use cases¶
Dependency parsing and chunking can be used as preprocessing steps for other NLP tasks. See for example the EPE shared task, where the performance of dependency parsers is evaluated through the ouput of downstream tasks such as:
Biological Event Extraction
Fine-Grained Opinion Analysis
Negation Resolution
It can also be used, for instance, for the extraction of keyphrases or for building a knowledge graph (see our tutorial).
Models¶
🔧 SpaCy¶
Read more about the SpaCy model in the dedicated SpaCy docs , it has also been trained using the Danish Dependency Treebank dataset.
Dependency Parser¶
Below is a small getting started snippet for using the SpaCy dependency parser:
from danlp.models import load_spacy_model
# Load the dependency parser using the DaNLP wrapper
nlp = load_spacy_model()
# Using the spaCy dependency parser
doc = nlp('Ordene sættes sammen til meningsfulde sætninger.')
dependency_features = ['Id', 'Text', 'Head', 'Dep']
head_format = "\033[1m{!s:>11}\033[0m" * (len(dependency_features) )
row_format = "{!s:>11}" * (len(dependency_features) )
print(head_format.format(*dependency_features))
# Printing dependency features for each token
for token in doc:
print(row_format.format(token.i, token.text, token.head.i, token.dep_))

Visualizing the dependency tree with SpaCy¶
# SpaCy visualization tool
from spacy import displacy
# Run in a terminal
# In jupyter use instead display.render
displacy.serve(doc, style='dep')
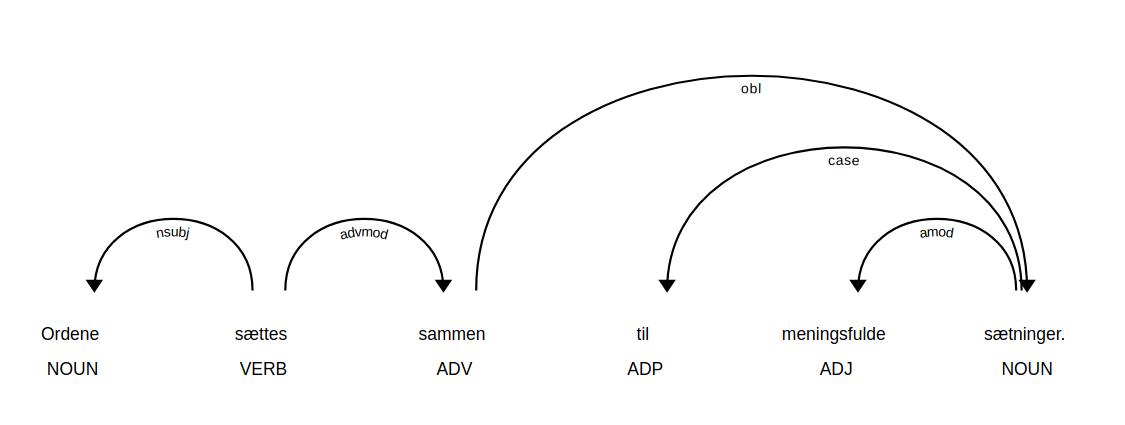
nsubj: nominal subject,
advmod: adverbial modifier,
case: case marking,
amod: adjectival modifier,
obl: oblique nominal,
punct: punctuation
Chunker¶
Below is a snippet showing how to use the chunker:
from danlp.models import load_spacy_chunking_model
# text to process
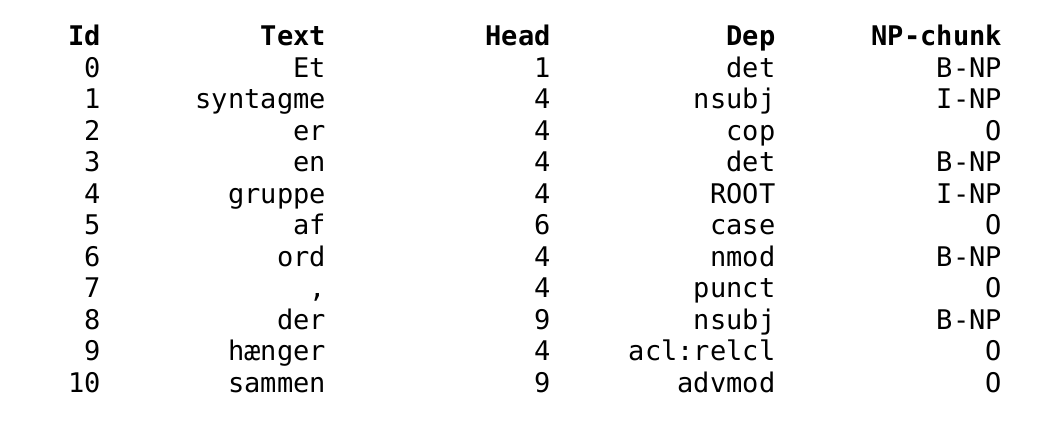
text = 'Et syntagme er en gruppe af ord, der hænger sammen'
# Load the chunker using the DaNLP wrapper
chunker = load_spacy_chunking_model()
# Using the chunker to predict BIO tags
np_chunks = chunker.predict(text)
# Using the spaCy model to get linguistic features (e.g., tokens, dependencies)
# Note: this is used for printing features but is not necessary for processing the chunking task
# OBS - The model loaded is the same as can be loaded with 'load_spacy_model()'
nlp = chunker.model
doc = nlp(text)
syntactic_features=['Id', 'Text', 'Head', 'Dep', 'NP-chunk']
head_format ="\033[1m{!s:>11}\033[0m" * (len(syntactic_features) )
row_format ="{!s:>11}" * (len(syntactic_features) )
print(head_format.format(*syntactic_features))
# Printing dependency and chunking features for each token
for token, nc in zip(doc, np_chunks):
print(row_format.format(token.i, token.text, token.head.i, token.dep_, nc))
DaCy¶
DaCy is a transformer-based version of the SpaCy model, thus obtaining higher performance, but with a higher computational cost. Read more about the DaCy model in the dedicated DaCy github, it has also been trained using the Danish Dependency Treebank dataset.
Stanza¶
Stanza is a python library which provides a neural network pipeline for NLP in many languages. It has been developed by the Stanford NLP Group. The Stanza dependency parser has been trained on the DDT.
📈 Benchmarks¶
See detailed scoring of the benchmarks in the example folder.
Dependency Parsing Scores¶
Dependency scores — LA (labelled attachment score), UAS (Unlabelled Attachment Score) and LAS (Labelled Attachment Score) — are reported below :
| Model | LA | UAS | LAS | Sentences per second (CPU*) |
|---|---|---|---|---|
| SpaCy | 87.68 | 81.36 | 77.46 | ~270 |
| DaCy (small) v0.0.0 | 91.42 | 87.26 | 84.2 | ~38 |
| DaCy (medium) v0.0.0 | 93.09 | 88.91 | 86.65 | ~6 |
| DaCy (large) v0.0.0 | 93.64 | 90.49 | 88.42 | ~1 |
| Stanza | 91.82 | 87.13 | 84.42 | ~9 |
Noun Phrase Chunking Scores¶
NP chunking scores (F1) are reported below :
| Model | Precision | Recall | F1 | Sentences per second (CPU*) |
|---|---|---|---|---|
| SpaCy | 91.32 | 91.79 | 91.56 | ~240 |
*Sentences per second is based on a Macbook Pro with Apple M1 chip.